
J’ai fait cette carte du réseau twitter sur le mot « agriculteur ».
Elle a circulé le 19 juin à l’occasion du colloque Afia les « Réseaux Sociaux et l’agriculture » qui s’est tenu à Paris et qui a regroupé une cinquantaine de personnes. Cette carte a fait un petit buzz car elle a été retweeté un bon nombre de fois (en tout cas à mon échelle).
Je vais décrire ici comment je l’ai créé à partir des données de twitter et à l’aide de deux outils : NodeXL et Gephi. Et la commenter!

Carte du mot agriculteur sur twitter
La réalisation de la carte
J’ai réalisé cette cartographie en utilisant plusieurs tutoriels en anglais. Il suffit de chercher un peu sur le net pour trouver de très bon tuto et des vidéos sur youtube, donc je ne vais pas trop détailler la procédure mais surtout commenter mon expérience. La première étape consiste à télécharger les données que l’on souhaite cartographier pour en faire un sociogramme. En l’occurrence je m’intéresse ici aux données de twitter. On pourrait faire le même type de carte avec facebook ou d’autres sources de données. Pour débuter je trouvais twitter plus intéressant et simple d’utilisation.
La première étape consiste à utiliser l’outil NodeXL, qui est un classeur Excel (template) fonctionnant avec Excel 2007, 2010, 2013. Cet outil permet de faire des cartes de réseaux, mais leur rendu étant moins sympa que Gephi, je me servirai uniquement de NodeXl pour charger les données de l’API twitter.
Une fois NodeXl téléchargé et que vous l’avez lancé (il suffit de lancer le fichier NodeXL.xlsx), il faut cliquer sur Importer. La fenêtre d’importation permet de saisir toutes les infos nécessaires à l’importation des données. Si vous souhaitez faire une importation par mot-clé, il vous suffit de le saisir dans la zone de texte prévue. Vous pouvez aussi utiliser les opérateur de recherche de twitter pour combiner des mots. Pour mon importation, j’ai choisi l’option « basic network plus friends », pour importer les nœuds connectés au comptes qui contiennent le mot clé recherché : agriculteur. Le temps de chargement sera long avec cette cette option car il y a plus de nœuds à charger. Il faut ensuite autoriser l’accès à l’API de twitter. pour cela il faut disposer d’un compte twitter et l’utiliser. Une authentification est nécessaire la première fois. La vraie contrainte est la limitation de l’API de twitter qui limite le nombre de requêtes (rate limit). Mais NodeXL gère cela parfaitement. Vous pouvez limiter le nombre de tweets que vous souhaitez obtenir. En cas de dépassement du trafic requêté, NodeXL effectuera des pauses de 15 minutes à chaque requête pour respecter les conditions d’accès de l’API. Il faut savoir que ma requête sur le mot agriculteur a mis plus de 24h… Il faut donc régler son ordinateur pour ne pas qu’il se mette en veille sinon vous devrez tout recommencer…
Une fois que votre requête s’est correctement exécutée vous devez retrouver dans les onglets « Edges » et « Vertices » les données. Il peut être utile de vérifier le nombre de lignes de ces onglets. Pour comprendre votre carte vous aurez à revenir dans ce fichier plus tard pour analyser le contenu des tweets. A ce stade, il suffit de retenir que dans l’onglets « vertices », on va retrouver les comptes twitters impliqués dans la requête (les nœuds), et dans l’onglet « edges », les relations entre les nœuds (follows, mentions, reply to, tweet).
Il est tout à fait possible de créer des sociogrammes avec NodeXL. Mais le rendu étant plus beau dans Gephi, je préfère passer les données dans ce deuxième outil. Pour cela il suffit d’exporter les données au format Graphml (Export/To Graphml file) et de télécharger le logiciel Gephi.
Une fois Gephi lancé, il faut cliquer sur ouvrir, puis sélectionner le fichier graphml enregistré précédement. A l’ouverture de l’assistant d’importation laisser les options par défaut et cliquer sur OK. L’environnement de Gephi comprend 3 onglets (vue d’ensemble, laboratoires des données, prévisualisation). L’essentiel du travail va se faire depuis l’onglet « vue d’ensemble ». Au départ, on retrouve un gros paquet gris comprenant les nœuds et les liaisons. Il n’y a aucun classement à ce stade. Tout le reste du travail va consister à appliquer des algorithmes pour classer les données et rendre le graphe lisible.
Pour cela il faut aller dans le menu « Statistique’ (à droite de l’écran). Nous allons dans un premier temps affecter des tailles différentes aux nœuds selon leur importance (c’est à dire leur nombres de connexions). Je commence par appliquer la méthode « Centrality Eigenvector » (en cliquant sur exécuter). Je laisse les données par défaut et je clique sur OK, un graphique de distribution apparaît, cliquer sur Fermer. Rien ne change dans notre sociogramme. Pour appliquer graphiquement l’algorithme, il faut aller dans le menu « Classement » (à droite de l’espace de travail), rester sur l’onglet « Nœud », cliquer sur le diamant rouge (qui représente la taille/poids) et choisir le paramètre de classement « eigencentrality » (il faut peut être rafraîchir la liste s’il n’apparaît pas), puis cliquer sur appliquer. Pour jouer sur la taille des nœuds, vous pouvez bouger les curseurs. A ce stade, vous voyez des nœuds plus gros que d’autres apparaître, mais cela reste encore assez confus.
Nous allons ensuite appliquer des regroupements. Dans le menu « Statistique », nous allons exécuter l’algorithme « Modularité ». On laisse les options par défaut et on ferme le graphique de distribution. Ensuite pour appliquer graphiquement cet algorithme nous allons dans le menu « Partition » (à gauche). En cliquant sur la double flèche verte, on rafraîchi la liste déroulante de ce menu. Choisir « Modularity Class », puis appliquer. Les nœuds vont alors se colorer selon leur « communauté », formant des classes de couleur dépendant de leur proximité.
Reste ensuite à appliquer une méthode de spatialisation pour répartir dans l’espace de façon plus lisible les nœuds (les nœuds vont s’écarter et se regrouper par classe de couleur). Il faut faire des essais et retenir l’algorithme qui vous plait le plus. Dans mon cas, j’ai retenu « Force Atlas ». Enfin, j’ai choisi de faire apparaître les labels (les noms des comtes twitter, en cliquant sur la lettre « T » en bas de la carte). Il faut ajuster la taille, puis exécuter à nouveau un script de spatialisation (ajustement des labels). Il est possible de retirer certains nœuds non significatifs s’il y en a encore trop de nœuds et que le graphe est illisible. Pour cela, il faut jouer avec les filtres du menu « Filtre » » à droite. En l’occurrence, j’ai utilisé le filtre « plage de degrés » de la catégorie « topologie ». En jouant sur les curseurs, j’ai nettoyé un peu mon graphe en retirant des nœuds qui ont peu de liaisons avec les autres.
La finalisation du rendu se fait dans l’onglet « Prévisualisation », là il faut faire des essais avec les propriétés du graphe.
La description de la carte
La carte obtenue présente 5 groupes de couleur. La groupe jaune est très représentatif de la twittosphère agricole avec des comptes très connus comme les sites d’information agricole : terrenetfr, wikiagri, franceagricole, lavieagricole,… ou des personnalités qui twittent beaucoup comme herve_pillaud, cathdagorn, remdumdum, bourgemain,… Ces comptes on tweeté ou retweeté plusieurs fois le mot « agriculteur » sur la période requêtée (du 29/05/2015 au 06/06/2015). Leur proximité explique la taille élevée des bulles et leur regroupement.
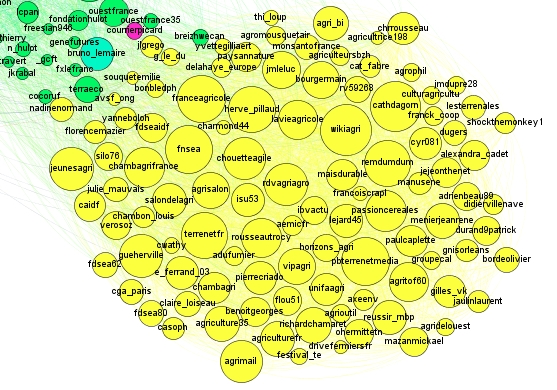
Le groupe vert au centre de la carte comprends de nombreux site d’information généralistes comme lemondefr, franceinfo, 20mintutes, afpfr, le_figaro. Leur proximité s’explique par le fait qu’ils sont tous des sites d’info généralistes qui se suivent. Mais pourquoi sont ils présents dans cette cartographie? Il se trouve qu’ils ont tweetés ou retweettés une info concernant un fait d’hiver (meurtre dans une truffière) impliquant un agriculteur.
Meurtre dans une truffière: 12 ans de réclusion requis contre un agriculteur http://t.co/uN4JUF937U #AFP
— Agence France-Presse (@afpfr) 29 Mai 2015
//platform.twitter.com/widgets.jsPlus troublant encore, le groupe turquoise en haut de la carte, constitué d’un grand nombre de comptes avec des petites bulles. On y retrouve plusieurs comptes de personnalité ou de sympathisants du front national o d’extrême droite (marion_m_lepen, elyseemarine,…) ! Il se trouve que durant cette période, il y a eu un tweet, extrêmement retweeté dans cette communauté avec le mot agriculteur… la proximité des comptes a fait le reste…
Soutien total à mon ami Philippe #Layat, le dernier agriculteur de #Décines exproprié par @gerardcollomb et @JM_Aulas pic.twitter.com/oyKVSAgHNt — Romain Vaudan (@RVaudan) 1 Juin 2015
//platform.twitter.com/widgets.js
Le groupe bleu est un groupe de chaînes de télé (france2tv, télé2semaines, morandinibiog,…)
Enfin le groupe rouge, très atypique, est constitué du fan club de Kev Adams. Celui-ci a tweeté une photo de lui parodiant un agriculteur. Le tweet a été retweeté par son fan club…
Kevin, 23 ans, jeune agriculteur à la recherche de l’amour.@kevadamsss pic.twitter.com/XQ3l95cSFx
— MERCI KEV (@laura_hnq) 29 Mai 2015
//platform.twitter.com/widgets.js
Et voilà l’explication de cette carte qui n’a de sens que prise dans son contexte (période de requête) et en explorant les données ! Vous pouvez désormais réaliser les vôtres et les partager… De mon côté, je pense que je vais en faire d’autres.


